
By
Vladislav Kotsev
April 2, 2026
6 min



When mechanics inspect a commercial airliner before a flight, they don't just turn the engine on, listen to it hum, and say, "Sounds right to me." Because human lives are on the line, that surface-level check is dangerously inadequate. Instead, they use specialized X-ray equipment to peer deep inside the machinery, checking for microscopic cracks inside every individual turbine blade.
As a blockchain architect building on Solana, I view our work through a similar lens.
The programs we write and deploy handle real-world business operations, and the financial stakes are high. Yet, historically, a lot of standard testing in the blockchain space has been the equivalent of just listening to the engine run. You write a test, you simulate a transaction, it returns a Ok((), and you ship it.
But what about the execution paths that weren't triggered? What about the obscure error-handling blocks or the dead code lingering in the depths of your instruction logic? To build truly resilient infrastructure, we need our own version of that X-ray machine. We need line-level visibility.
In my day-to-day work, I focus heavily on optimizing how we write and verify Solana programs. In the last year, I’ve been gradually transitioning away from Anchor's heavier, legacy frameworks toward a much leaner, more precise stack.
For CU-sensitive applications and program architecture, I’ve been building with the Pinocchio library. It is a minimal Solana program framework that strips away the overhead, giving us raw, unfiltered access to Solana's execution environment to save compute units. This comes at a cost: you're responsible for safety. But the reward is significant: programs that are smaller, faster, and cheaper to execute.
To demonstrate this, let's look at a classic atomic swap pattern: a Token Escrow. Our escrow program supports two instructions:
When you strip away the macros, your project structure becomes incredibly focused:
escrow/
├── Cargo.toml
├── Makefile.toml
├── src/
│ ├── lib.rs # Entrypoint + instruction dispatch
│ ├── constants.rs # Seed constants
│ ├── state/
│ │ ├── mod.rs
│ │ └── escrow.rs # Escrow account state
│ └── instructions/
│ ├── mod.rs
│ ├── helpers.rs # Reusable account validation helpers
│ ├── make.rs # Make instruction
│ └── take.rs # Take instruction
└── tests/
├── make_test.rs
└── take_test.rs
The escrow account stores who created it, which mints are involved, how much Token B is expected, and the PDA derivation parameters. Using Pinocchio, we don't own the data; we borrow it to achieve zero-copy deserialization:
use pinocchio::Address;
use wincode::{SchemaRead, SchemaWrite};
#[repr(C)]
#[derive(SchemaRead, SchemaWrite)]
pub struct Escrow<'a> {
maker: &'a [u8; 32],
mint_a: &'a [u8; 32],
mint_b: &'a [u8; 32],
receive: &'a u64,
seed: &'a u64,
bump: &'a u8,
}
impl<'a> Escrow<'a> {
// Manual size calculation: 3*(32) + 2*(8) + 1 = 113 bytes
pub const LEN: usize = 3 * size_of::<[u8; 32]>() + 2 * size_of::<u64>() + size_of::<u8>();
}#[repr(C)] ensures a predictable memory layout. Combined with wincode's derives, the struct creates pointers into the existing byte slice rather than making expensive copies of it.
The entrypoint is completely devoid of magic. A single byte dictates the dispatch:
use pinocchio::{AccountView, Address, ProgramResult, entrypoint, error::ProgramError};
use pinocchio_pubkey::declare_id;
declare_id!("4AtAjt1xrf6SwnwSh8GjnTJFrkMVZBscPSKKaFG8mQam");
entrypoint!(process_instruction);
pub fn process_instruction(
_program_id: &Address,
accounts: &[AccountView],
instruction_data: &[u8],
) -> ProgramResult {
let [disc, data @ ..] = instruction_data else {
return Err(ProgramError::InvalidInstructionData);
};
match disc {
Make::DISCRIMINATOR => Make::try_from((accounts, data))?.process(),
Take::DISCRIMINATOR => Take::try_from((accounts, data))?.process(),
_ => Err(ProgramError::InvalidInstructionData),
}
}
When processing instructions, such as Make, we explicitly handle PDA creation, state initialization, and token transfers via Cross-Program Invocations (CPIs):
pub fn process(&self) -> ProgramResult {
// 1. Create the escrow PDA account
let seeds = &[ /* ... */ ];
ProgramAccount::init::<Escrow>(self.accounts.maker, self.accounts.escrow, seeds, space)?;
// 2. Create vault ATA owned by escrow
AssociatedToken::init(self.accounts.vault, self.accounts.mint_a, /* ... */)?;
// 3. Write escrow state
let mut escrow = deserialize_mut::<EscrowMut>(escrow_account_data)?;
escrow.set_inner(maker, mint_a, mint_b, &receive, &seed, &bump);
// 4. Transfer tokens from maker's ATA to vault
Transfer { from: self.accounts.maker_ata, authority: self.accounts.maker,
to: self.accounts.vault, amount: self.data.amount }.invoke()
}
However, a lean architecture like this must be paired with comprehensive testing to ensure its reliability in production.
To test these programs, we utilize the Mollusk testing framework. Mollusk directly invokes the Solana Virtual Machine (SVM) instruction processor locally. It lets us spin up the engine quickly and efficiently.
Setting it up is straightforward:
// We initialize mollusk with debuggable constructor, we will need it later.
let mut mollusk = Mollusk::new_debuggable(&PROGRAM_ADDRESS, "target/deploy/escrow", true);
Mollusk requires you to provide all accounts manually. This forces you to intimately understand the exact state your program interacts with:
// Create a token account manually for the test state
let maker_a_data = TokenAccount {
mint: mint_a_address,
owner: maker_address,
amount: 1_000_000,
delegate: COption::None,
state: AccountState::Initialized,
is_native: COption::None,
delegated_amount: 0,
close_authority: COption::None,
};
let (maker_a_ata_address, maker_a_ata_account) =
create_account_for_associated_token_account(maker_a_data);
But again, running the engine isn't enough. We need the X-ray.
This is exactly what sbpf-coverage provides. When you run your Mollusk tests combined with sbpf-coverage, you stop guessing. The tool maps the executed SBPF (Solana Berkeley Packet Filter) instructions directly back to your Rust source code.
It provides line-level visibility. It tells you exactly which lines of code your tests touched and, more importantly, which ones they missed. If there is a hidden panic, an untested arithmetic overflow check, or a branch of logic that your tests simply never reach, sbpf-coverage shines a light right on it.
Instead of meticulously editing your Cargo.toml to alter your release profiles (which can be a pain in the a** and easily committed by mistake) you might as well skip editing files entirely. You can build the Solana programs by hand, passing the exact compiler arguments you need directly via RUSTFLAGS.
Simply run the following build command:
RUSTFLAGS="-Copt-level=0 -C strip=none -C debuginfo=2" cargo build-sbf --tools-version v1.54 --arch v1 --debug
Note: The [profile.release] section settings are mandatory. Without them, your X-ray machine will be blurry and inaccurate.
Using this tooling stack ensures that no hidden errors or untested paths exist in the deepest parts of your program system before it goes live.
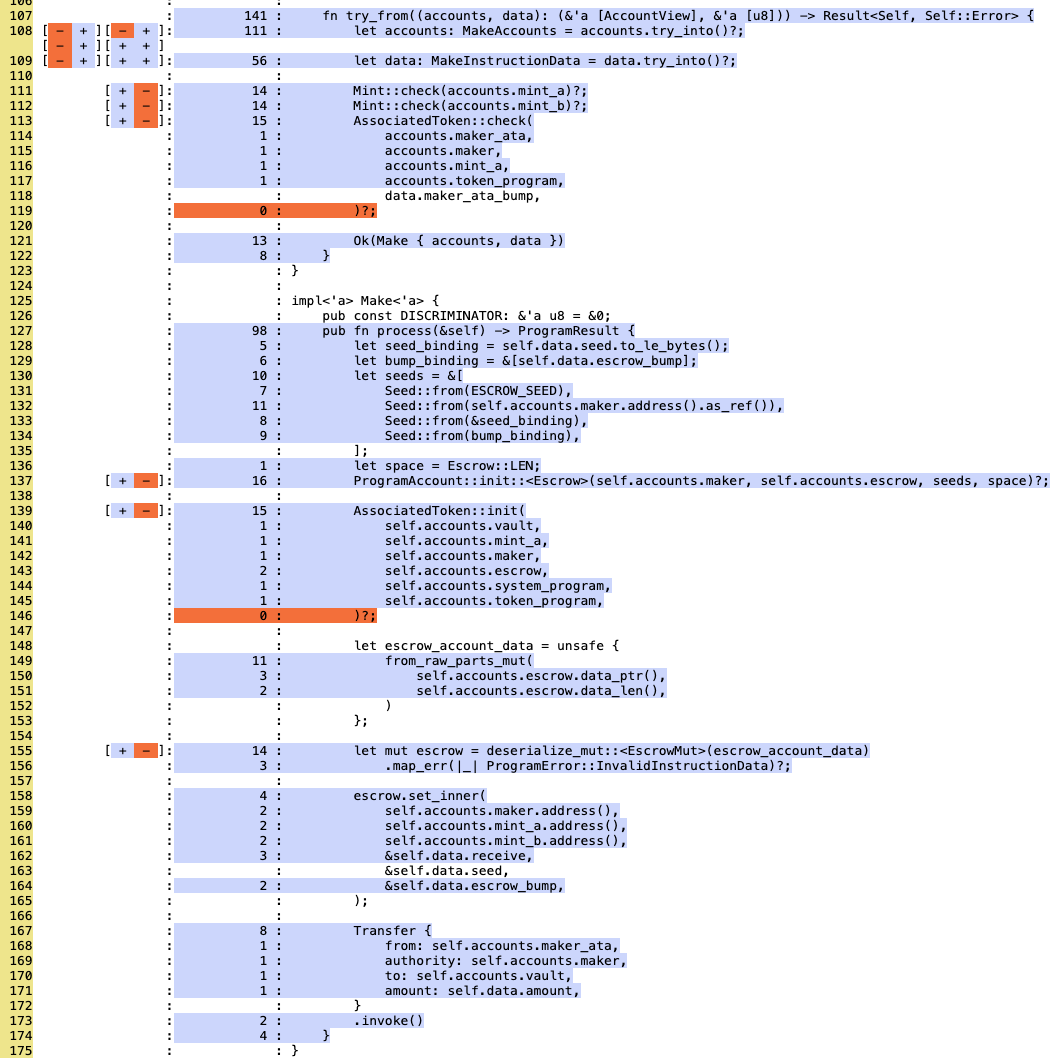
To demonstrate how this architecture and testing methodology come together, I put together a comprehensive proof-of-concept.
I recently prepared a full escrow example program built entirely with this new stack. It's a classic Solana escrow implementation, but the value lies under the hood in how it is structured and tested. It uses Pinocchio for the program logic, Mollusk for the test environment, and leverages sbpf-coverage to ensure line-level scrutiny.
I believe that if we truly want Solana to serve as the baseline for global financial infrastructure, we have to adopt aviation-grade engineering standards. We can't afford to just listen to the engine anymore.
I invite you to dive into the repository, inspect the code, and see the testing harness in action. You can check out the framework and the full implementation here: https://github.com/vlady-kotsev/escrow-pinocchio-0.10
Feel free to reach out and connect. I'm always happy to nerd out with fellow developers passionate about high-performance architecture. Peace. ✌️
Or just shoot us a message on Telegram




